Processing a large video file in parallel
a job-scheduling implementation
If I can point a good thing brought in by the 2021 pandemic is that my family got closer. We are distributed in three continents and in order to "check on each other", we started to have weekly video calls. Some time ago we had a long one to celebrate my mother’s birthday. I took the chance to record the entire event as a memento of the crazy times we are going through. Once it finished, I attempted to upload the video to Google Photos, only to realize that the file was too big leading the service to refuse the upload because it lacked space.
Knowing nothing about video files I did a quick search for anything that could reduce its size. I’ve copied some instructions for FFmpeg (a cross-platform solution to record, convert and stream audio and video) from StackOverflow and, while painfully waiting for my 2018 Macbook Pro to finish whatever it was doing, I started to think if I could use my Raspberry Pi cluster to speed up this process. This was the beginning of a personal project that definitely took longer than I’ve would expect, but that taught me many interesting things.
Video File Basics
After rushing through some initial ideas I decided that I needed a basic understanding of video files, what is it that causes their size to grow, and how we can manipulate them to occupy less space without losing too much quality. The information I found is only a scratch on what there is to know about the topic but it was enough to help me keep going through.
There are a number of factors that determine video quality. In the end, there is no absolute answer, the quality will depend on who assesses it. Despite that, there are a couple of parameters that play a key role in how quality is commonly perceived. These parameters are the video resolution, which means the number of pixels used to display an image, the bitrate which tells how much data is streamed in a given unit of time (usually expressed kilobits per second), and the framerate, which indicates the number of frames (images) that happens in a unit of time.
These parameters are independent of each other and yet they will impact the video quality (and size). For example, a large resolution with a low framerate will show each frame with high-definition but with a choppy/blurry movement, a high framerate will smooth the movements but if the resolution is low the image will not be sharp. Lastly, the higher the framerate and/or resolution the higher it will be the bitrate served and, consequently, the size of the file.
There are other factors that can influence the file size, for example, the bitrate type, Constant Bit Rate (CBR) which is good for streaming, or Variable Bit Rate (VBR) which is optimized for video size. Another important piece of this puzzle is video encoding. Simply put, video encoding is the process of preparing the raw video data to be stored and later played. An important part of the video encoding process is video compressing, which accounts for manipulating the video data to reduce size with minimal loss of quality.
The process of storing the video optimally is called encoding. This state of the video makes it good to be stored and transmitted however it makes it unplayable. In order to make the video playable, it needs to be decoded in a way that the player can interpret it. The tools that transform the video between these two states can be implemented in software or hardware and they are called codecs.
H.264, or Advanced Video Coding (AVC), is a popular video compression standard, utilized by most of the video industry, still in 2019. There is a multitude of codecs that we can choose from. A particularly interesting one is AVC’s successor, the High Efficient Video Coding (HEVC) or H.265 which provides a more efficient compression without losing quality, which makes it great for streaming of high-definition videos. The problem with re-encoding is that it can increase the processing time. There are hardware codecs that typically generate an output of significantly lower quality than good software encoders, like x264, but they are generally faster and do not use much CPU resources.
Source: Understanding Video Quality and Parameters, What is video encoding?
Analyzing the source
With this basic understanding, let’s take a look at my video to identify what, other than the large duration, was causing it to be that big:
ffmpeg -i input.mov...Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuvj420p(pc, bt709), 1920x1080 [SAR 1:1 DAR 16:9], 23060 kb/s, 60 fps, 60 tbr, 6k tbn, 12k tbc (default)…
The output tells us that the codec used for the video recording is H.264, the resolution was FullHD (1920 x 1080) and it had 60 frames per second. These parameters were, of course, much higher than what I needed. My video was a screen recording of several webcams that, themselves, do not produce a video with a quality higher than 720p. We were sitting most of the time with no further action than my nephews occasionally jumping around in the living room, hence 60 frames per second were beyond optimal. Lastly, the bit rate could be made variable since I wasn’t intending to stream anything.
Based on this information, I decided that downscaling the video via resolution, framerate, and variable bitrate would already give me a reasonable file size without incurring the extra cost of running the encoder for too long or sacrificing the output size/quality for speed in case I went with the hardware option. The final configuration was set on H.264 as de video codec, resolution downscaled from 1080p to 720p and FPS decreased from 60 to 24. This can be done with the following FFmpeg command:
ffmpeg -i input.mov -vf scale=-1:720 -r 24 -crf 30 -pix_fmt yuv420p output.movJob scheduling
In order to take advantage of the several CPUs I had laying around (a MacbookPro 2018, a MacbookPro late 2013, and a Raspberry Pi Cluster with 4 Raspberry Pi 4 Model B), I had to first split the video file into smaller parts of identical size — for that, I’ve used MP4Box CLI, the multimedia packager available in GPAC. The idea was to process these smaller chunks in this cluster. In order to achieve the minimum processing time, I needed to allocate how many files each machine would process. For example, the MacbookPro 2018 would be obviously the fastest, not only because of the CPU but also because it would have no cost to move the files in, hence it should get more load. The Pi Cluster has the worst CPU times, therefore it should process fewer files, the MacbookPro 2013 should process something in between these two.
This problem is known as job-shop scheduling and in its simplest form can be defined as:
“We are given n jobs J1, J2, …, Jn of varying processing times, which need to be scheduled on m machines with varying processing power, while trying to minimize the makespan. The makespan is the total work time of the busiest machine.”
This problem is NP-hard, meaning that there is no known algorithm that can give its optimal solution in polynomial time — unless P = NP. The intuition of this conclusion can be achieved by reducing the Traveling Salesman Problem as a particular case of Job Scheduling Problem where the cities are the machines and the salesman is the job. In face of NP-hard problems, a typical approach is to use approximation algorithms, which are efficient algorithms to find approximation solutions for optimization problems.
A common approximation algorithm is the Greedy Algorithm, which consists of a heuristic of making the locally optimal choice at each iteration. In this particular problem, a proposed local optimal choice is to select the next-to-be idle machine to perform the allocation. This algorithm is known as List Scheduling and was proposed by L. B. Graham in 1966. Below is a sample implementation for this simplified version of the problem:
The job cost per machine can be given as:
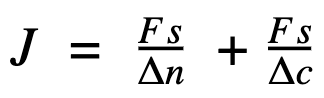
Where:
- J = the job duration
- Fs = the file size
- Δn = network speed
- Δc = the conversion speed
The split of the large file into smaller ones, the upload of the converted files back to the main node, and later merge of the converted parts into a single file are not taken into consideration for this experiment — in general, these are much cheaper processes when compared to the other components of the equation. Computing the rates above is tricky because they vary widely depending on how things were assembled. For example, in my experiment, I only had my internet provider router which gives me four ethernet ports (one for the master node and three for the Raspberry Pis, once I have no USB-B adapter for my old MacBook Pro). That said, this last node will have to remain connected via wi-fi. In this configuration, the furthest the node is from the router, the slower is the speed.
Manual computing all of these rates was proven to be difficult, even with the help of Iperf3, once predicting how much bandwidth to be given to each node while running the system is not trivial. I then decided to take another approach. Instead of trying to predict how many files to delegate to each machine, the nodes themselves would request a new file whenever they finished converting the files. During the experiment execution, I collected metrics to later use in the equation above and compare the obtained results.
Implementation
The proposed design is illustrated below:
I picked Python as the project language as it offers good libraries for this job while making it easy to interface with Shell — e.g. calling FFmpeg. The communication between the nodes was performed via HTTP using Flask as the web framework. The API is composed of an endpoint to serve the files, one to update the file status and another to upload the converted files — for simplicity I did not consider compressing the files to improve the network bottleneck.
I used Bazel and Google’s Subpar to generate a standalone executable Python that could be distributed to the workers via SCP. The node access requires it to have SSH configured with no password prompt, the authentication was key-based. I added virtual nodes running on both MacBooks, hence the project counts with a Docker file with all the dependencies bundled — for the Raspberry Pis, FFmpeg was installed via Ansible. A simple frontend was added in order to display the progress of the process, along with some metrics to understand the performance of the nodes.
Results
Applying the configuration to a 16Gb file across the cluster with 11 nodes (6 physical and 5 virtual) took 13 minutes to finish, producing a file of 224 MBytes — a disk improvement of ≈98,6%. The baseline for the process was obtained by executing the conversion of the main file in the Macbook Pro 2018, which took ≈23 minutes to finish. The speed gain was ≈44% or ≈10 minutes. Throughout the experiment, the average values for the network speed and the file conversion rate were captured per node. The results can be seen in the table below:
With the empirical values obtained from the experiment, we can go back to the list-scheduling algorithm and compare the obtained results:
As shown in the chart above, the total number of allocated jobs per machine remained very close to the setup output by the approximation algorithm proposed in the Job Scheduling section. The proposed algorithm delivered a makespan of ≈12minutes, the experiment obtained makespan was of ≈13 minutes.
Conclusion
The makespan difference between the approximation algorithm and the executed experiment can be attributed to the fact that some aspects of the job workflow were disregarded for the approximation algorithm, for example, the time to upload the converted files from the workers to the master node. Despite that, the obtained and computed results were very close — as expected, since the rates used for the calculation were derived from the execution.
The improvement of 98,6% in the file size is excellent, despite quality losses, the overall one obtained was satisfactory — as mentioned in the “Video File Basics” section, the quality depends on who assesses it. The ≈44% speed gain in the conversion speed can be further improved in different ways. The most obvious one is improving the experiment set up by connecting all the nodes via cable to the network, however, optimizations can also be made in the algorithm execution (currently a worker node waits for a file to be converted and uploaded back to the master node before requesting a new one).
This project took much longer than what I had initially planned, but it guided me through a very intriguing journey where I could learn a bit about the basics of how video files work, allowed me to use Flask, Bazel, and Subpar combo for the first time, introduced me to the parallel machine scheduling problem and allowed me to implement a solution that could solve it for this particular use case. I’m glad I decided to go on with it.
